#hide
# !pip install -Uqq fastbook
import fastbook
fastbook.setup_book()Classifying Track Bikes Using Neural Networks
Teaching neural nets to guess the manufacturer of a track bike.
- toc: true
- branch: master
- badges: false
- comments: false
- author: Nishan Mann
- categories: [fastpages, jupyter, neural networks]
This notebook has various goals - document initial attempts at using a CNN to classify track bikes - demonstrate the use of fastai python library to quickly build models - demonstrate the use of fastpages to convert Jupyter notebooks into blog posts
At the time of writing, please be aware of this bug and do not run v2.2.7 of the fastai library.
import pandas as pd
from fastbook import *
from fastai.vision.widgets import *All Makes Multi-Class Classfier
Loading and Preparing Data
This dataset was collected by manual scraping various public facebook pages of track day photographers and manually labelling each image. This is a painstaking process hence the lack of scale.
path_all_makes = Path("/home/nishan/Datasets/TrackBikes/")all_makes_db = DataBlock(
blocks=(ImageBlock, CategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(valid_pct=0.3, seed=42),
get_y=parent_label,
item_tfms=Resize(128))all_makes_dls = all_makes_db.dataloaders(path_all_makes)all_makes_dls.categorize.vocab['aprilia', 'bmw', 'ducati', 'honda', 'kawasaki', 'not_a_bike', 'suzuki', 'triumph', 'yamaha']- 8 classes of bikes and 1 class of not a bike. Hence this is a multiclass problem.
pd.Series([all_makes_db.get_y(fpath) for fpath in all_makes_db.get_items(path_all_makes)]).value_counts()yamaha 106
not_a_bike 66
kawasaki 61
suzuki 43
honda 37
bmw 23
aprilia 19
ducati 18
triumph 13
dtype: int64- this breakdown is before the random train test split
- class imbalance here is representative of reality: yamaha rules on the track! Yamaha makes excellent track bikesw with wide availabilty of parts. European branfs on the other hand such as Triumph or Ducati don’t fare well on the track due to their expensive upkeep.
all_makes_dls.show_batch()
- as one can see it is a hard job to tell one track bike from another, even veterans sometimes have a hard time
- there are also riders in the image that really don’t need to be there.
- there is one exception, not_a_bike images are clearly distinct
Train
learner_all_makes = cnn_learner(all_makes_dls,
resnet18,
metrics=[error_rate, F1Score(average="weighted")],
lr=0.001)
learner_all_makes.fine_tune(20)| epoch | train_loss | valid_loss | error_rate | f1_score | time |
|---|---|---|---|---|---|
| 0 | 3.387504 | 3.434762 | 0.843478 | 0.150317 | 00:07 |
| epoch | train_loss | valid_loss | error_rate | f1_score | time |
|---|---|---|---|---|---|
| 0 | 2.458725 | 2.720732 | 0.782609 | 0.238803 | 00:06 |
| 1 | 2.288914 | 2.325032 | 0.721739 | 0.297734 | 00:06 |
| 2 | 2.100991 | 2.084926 | 0.660870 | 0.350149 | 00:06 |
| 3 | 1.928781 | 1.972242 | 0.600000 | 0.390711 | 00:06 |
| 4 | 1.728745 | 1.952721 | 0.582609 | 0.403826 | 00:06 |
| 5 | 1.554006 | 1.984210 | 0.565217 | 0.418602 | 00:06 |
| 6 | 1.371065 | 2.067232 | 0.556522 | 0.425561 | 00:06 |
| 7 | 1.210570 | 2.109502 | 0.539130 | 0.447560 | 00:06 |
| 8 | 1.068196 | 2.182838 | 0.530435 | 0.452751 | 00:06 |
| 9 | 0.949947 | 2.231217 | 0.547826 | 0.439832 | 00:06 |
| 10 | 0.855398 | 2.246051 | 0.530435 | 0.464127 | 00:06 |
| 11 | 0.767150 | 2.230837 | 0.530435 | 0.464127 | 00:06 |
| 12 | 0.687040 | 2.237967 | 0.539130 | 0.457851 | 00:06 |
| 13 | 0.617871 | 2.246048 | 0.539130 | 0.457851 | 00:06 |
| 14 | 0.560617 | 2.254689 | 0.530435 | 0.466674 | 00:06 |
| 15 | 0.511584 | 2.272471 | 0.530435 | 0.466674 | 00:07 |
| 16 | 0.473674 | 2.285174 | 0.539130 | 0.454330 | 00:06 |
| 17 | 0.434411 | 2.279321 | 0.539130 | 0.454330 | 00:06 |
| 18 | 0.396292 | 2.275615 | 0.539130 | 0.455911 | 00:06 |
| 19 | 0.365418 | 2.275396 | 0.530435 | 0.461386 | 00:06 |
- due to class imbalance, error_rate is perhaps not the best measure of performance
- valid_loss is stagnant after epoch 14 while train_loss is decreasing. Hence the model is starting to overfit to the train set after epoch 14
- the weighted f1_score is ~0.46 which is quite bad
Eval
interp_all_bikes = ClassificationInterpretation.from_learner(learner_all_makes)interp_all_bikes.print_classification_report() precision recall f1-score support
aprilia 0.40 0.40 0.40 5
bmw 0.11 0.17 0.13 6
ducati 0.00 0.00 0.00 3
honda 0.33 0.19 0.24 16
kawasaki 0.50 0.40 0.44 15
not_a_bike 0.94 0.94 0.94 17
suzuki 0.40 0.25 0.31 16
triumph 0.50 0.33 0.40 3
yamaha 0.45 0.62 0.52 34
accuracy 0.47 115
macro avg 0.40 0.37 0.38 115
weighted avg 0.47 0.47 0.46 115
interp_all_bikes.plot_confusion_matrix(dpi=100)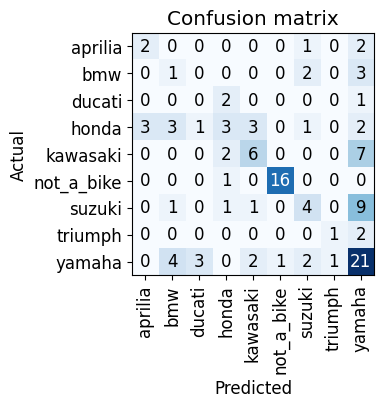
- the first thing to note is the lack of labelled data in the validation set for some classes
- for example, ducati has 3 images while yamaha has 34, bmw has 6
- not_a_bike class does the best. this means the classifier has indeed figured out what constitutes a motorcycle. This could be because during the training of resnet, one class was actually motorcycle.
- suzuki is often confused with yamaha
- honda is the most confused of all classes
- most bike classes get confused with yamaha
interp_all_bikes.most_confused(2)[('suzuki', 'yamaha', 9),
('kawasaki', 'yamaha', 7),
('yamaha', 'bmw', 4),
('bmw', 'yamaha', 3),
('honda', 'aprilia', 3),
('honda', 'bmw', 3),
('honda', 'kawasaki', 3),
('yamaha', 'ducati', 3),
('aprilia', 'yamaha', 2),
('bmw', 'suzuki', 2),
('ducati', 'honda', 2),
('honda', 'yamaha', 2),
('kawasaki', 'honda', 2),
('triumph', 'yamaha', 2),
('yamaha', 'kawasaki', 2),
('yamaha', 'suzuki', 2)]interp_all_bikes.plot_top_losses(9,figsize=(18, 18))
Challenges in classification - lack of data - the rider adds unnecessary noise - different orientations of the bike - there are genuinely very few features from the bodywork that separate the makes - bike is not always center in the picture - make contains different models R6 R1 just in yamaha for example
# interp_all_bikes.top_losses()
# interp_all_bikes.preds
# learner_all_makes.get_preds()
# y_probs, y_preds = learner_all_makes.get_preds(dl=dls_all_makes.valid)
# y_probs
# y_preds
# dls_all_makes.valid.vocab
# y_preds.where(y_preds == 4, torch.scalar_tensor(0))
# torch.scalar_tensor(0,)
# dls_all_makes.valid.categorize?
# dls_all_makes.valid.itemsYamaha or Not Multi-Class Classifier
We now try an easier problem, is the trackbike a {Yamaha, Not a Yamaha, Not a bike}. Since we’ve a lot of Yamahas in our labelled dataset, by bunching not Yamahas into one class, hopefully we can alleviate the class imbalance problem.
path_yamaha_binary = Path("/home/nishan/Datasets/YamahaBinary/")yamaha_binary_db = DataBlock(
blocks=(ImageBlock, CategoryBlock),
get_items=get_image_files,
splitter=RandomSplitter(valid_pct=0.2, seed=42),
get_y=parent_label,
item_tfms=Resize(128))
# other possible datablocks. Mainly they differ in the transforms applied to the images
# bikes = DataBlock(
# blocks=(ImageBlock, CategoryBlock),
# get_items=get_image_files,
# splitter=None,
# get_y=parent_label,
# item_tfms=Resize(128))
# bikes = bikes.new(
# item_tfms=RandomResizedCrop(224, min_scale=0.5),
# batch_tfms=aug_transforms())
# bikes = bikes.new(
# item_tfms=RandomResizedCrop(224, min_scale=0.5),
# batch_tfms=None)
# dls = bikes.dataloaders(path_trackbikes)
# bikes = bikes.new(
# item_tfms=Resize(224, ResizeMethod.Squish),
# batch_tfms=aug_transforms())
# bikes = bikes.new(
# item_tfms=Resize(224, ResizeMethod.Pad, pad_mode='zeros'),
# batch_tfms=None)pd.Series([yamaha_binary_db.get_y(fpath) for fpath in yamaha_binary_db.get_items(path_yamaha_binary)]).value_counts()not_yamaha 224
yamaha 165
not_a_bike 66
dtype: int64- the value count for yamaha doesn’t align with the previous section because I added more bikes when assembling this dataset
- class imbalance is now partially alleviated as we have more not yamahas
yamaha_binary_dls = yamaha_binary_db.dataloaders(path_yamaha_binary)yamaha_binary_dls.show_batch(max_n=6, nrows=2)
- you can see that the cropping sometimes takes out the bike from the image
Train
learner_yamaha_binary = cnn_learner(yamaha_binary_dls,
resnet18, metrics=[error_rate, F1Score(average="weighted")],
lr=0.001)
learner_yamaha_binary.fine_tune(20)| epoch | train_loss | valid_loss | error_rate | f1_score | time |
|---|---|---|---|---|---|
| 0 | 1.930770 | 1.247743 | 0.329670 | 0.624340 | 00:07 |
| epoch | train_loss | valid_loss | error_rate | f1_score | time |
|---|---|---|---|---|---|
| 0 | 1.424345 | 0.862586 | 0.329670 | 0.651071 | 00:07 |
| 1 | 1.304576 | 0.737989 | 0.296703 | 0.705542 | 00:07 |
| 2 | 1.214939 | 0.711476 | 0.252747 | 0.744928 | 00:07 |
| 3 | 1.092670 | 0.700428 | 0.263736 | 0.731569 | 00:07 |
| 4 | 0.979581 | 0.731643 | 0.263736 | 0.725127 | 00:07 |
| 5 | 0.886004 | 0.733914 | 0.274725 | 0.724728 | 00:07 |
| 6 | 0.779175 | 0.749347 | 0.274725 | 0.725338 | 00:07 |
| 7 | 0.675493 | 0.742499 | 0.274725 | 0.719206 | 00:07 |
| 8 | 0.592519 | 0.745616 | 0.296703 | 0.689342 | 00:07 |
| 9 | 0.531942 | 0.762820 | 0.296703 | 0.693753 | 00:07 |
| 10 | 0.467197 | 0.800540 | 0.296703 | 0.697521 | 00:07 |
| 11 | 0.413226 | 0.844249 | 0.296703 | 0.700701 | 00:07 |
| 12 | 0.369834 | 0.868356 | 0.285714 | 0.713129 | 00:07 |
| 13 | 0.328100 | 0.861939 | 0.274725 | 0.725338 | 00:07 |
| 14 | 0.294613 | 0.849984 | 0.263736 | 0.735216 | 00:07 |
| 15 | 0.267953 | 0.865282 | 0.285714 | 0.715429 | 00:07 |
| 16 | 0.241579 | 0.875345 | 0.274725 | 0.727325 | 00:07 |
| 17 | 0.219295 | 0.864667 | 0.285714 | 0.715429 | 00:07 |
| 18 | 0.198167 | 0.866620 | 0.274725 | 0.727325 | 00:07 |
| 19 | 0.182071 | 0.863331 | 0.274725 | 0.727325 | 00:07 |
- the model now has an accepetable weighted f1_score of around ~0.72
Eval
interp_yamaha_binary = ClassificationInterpretation.from_learner(learner_yamaha_binary)interp_yamaha_binary.plot_confusion_matrix(dpi=100)
interp_yamaha_binary.print_classification_report() precision recall f1-score support
not_a_bike 0.93 1.00 0.96 13
not_yamaha 0.79 0.73 0.76 51
yamaha 0.53 0.59 0.56 27
accuracy 0.73 91
macro avg 0.75 0.77 0.76 91
weighted avg 0.73 0.73 0.73 91
- its still challenging to predict a yamaha for a yamaha. the precision and recall for yamaha class is the worst
- not a bike class is the easiest and brings up the weighted f1 score.
- not_yamaha precision and recall are acceptable
interp_yamaha_binary.plot_top_losses(9, nrows=3, figsize=(18, 18))
- how much does the rider affect the model?
Production Demo
For a quick interactive demo of the model, launch binder or see this repo for more information.